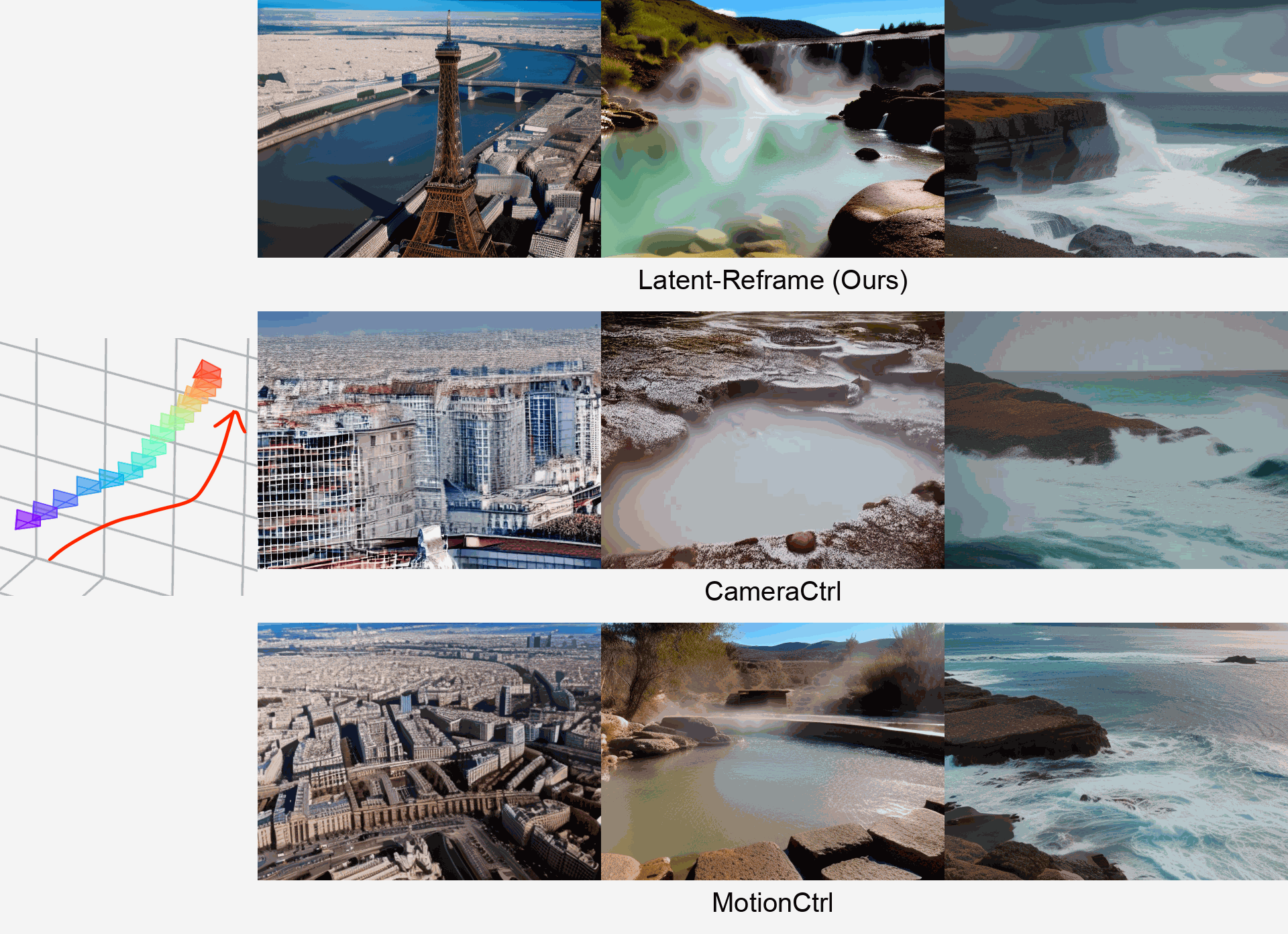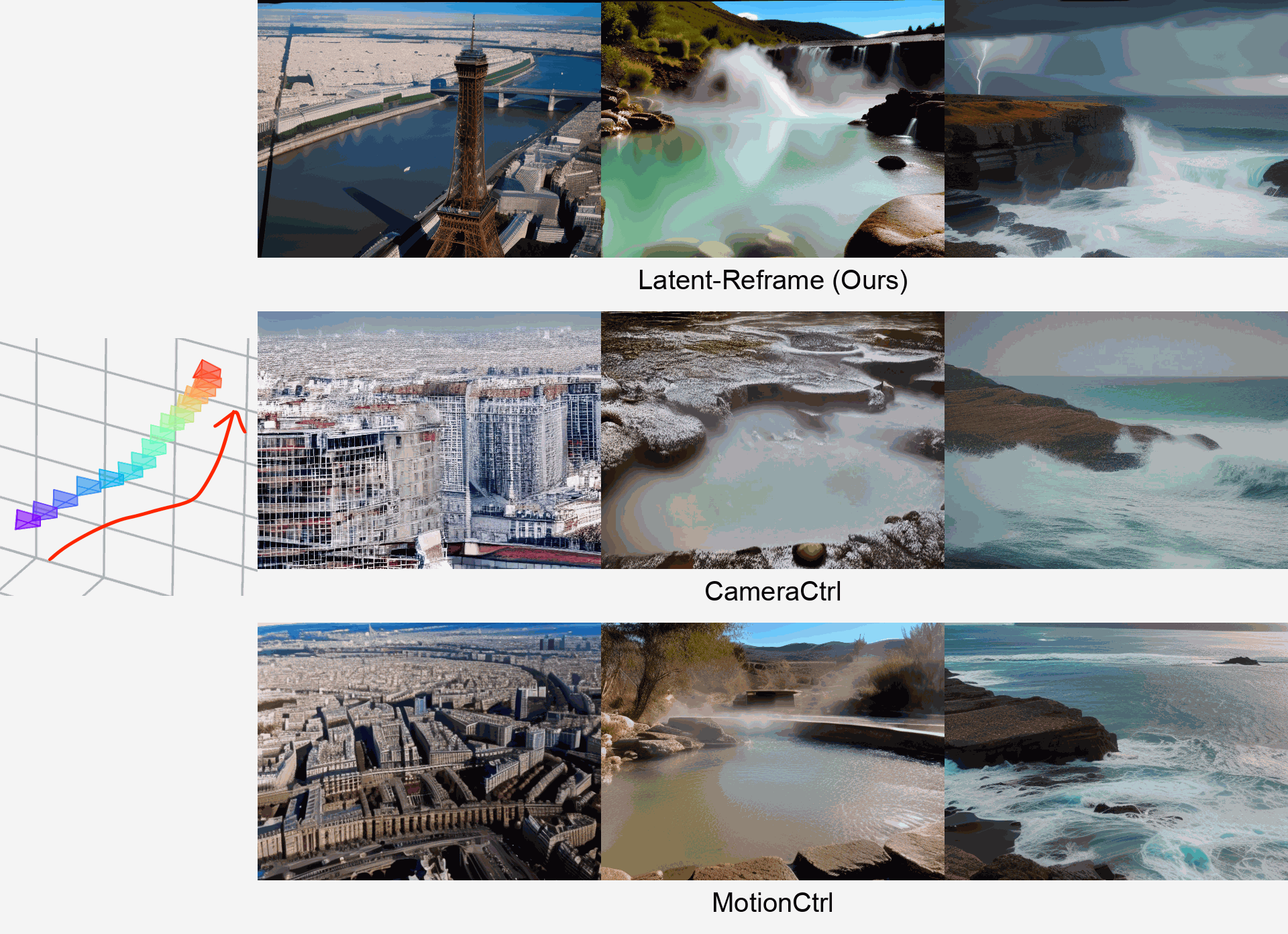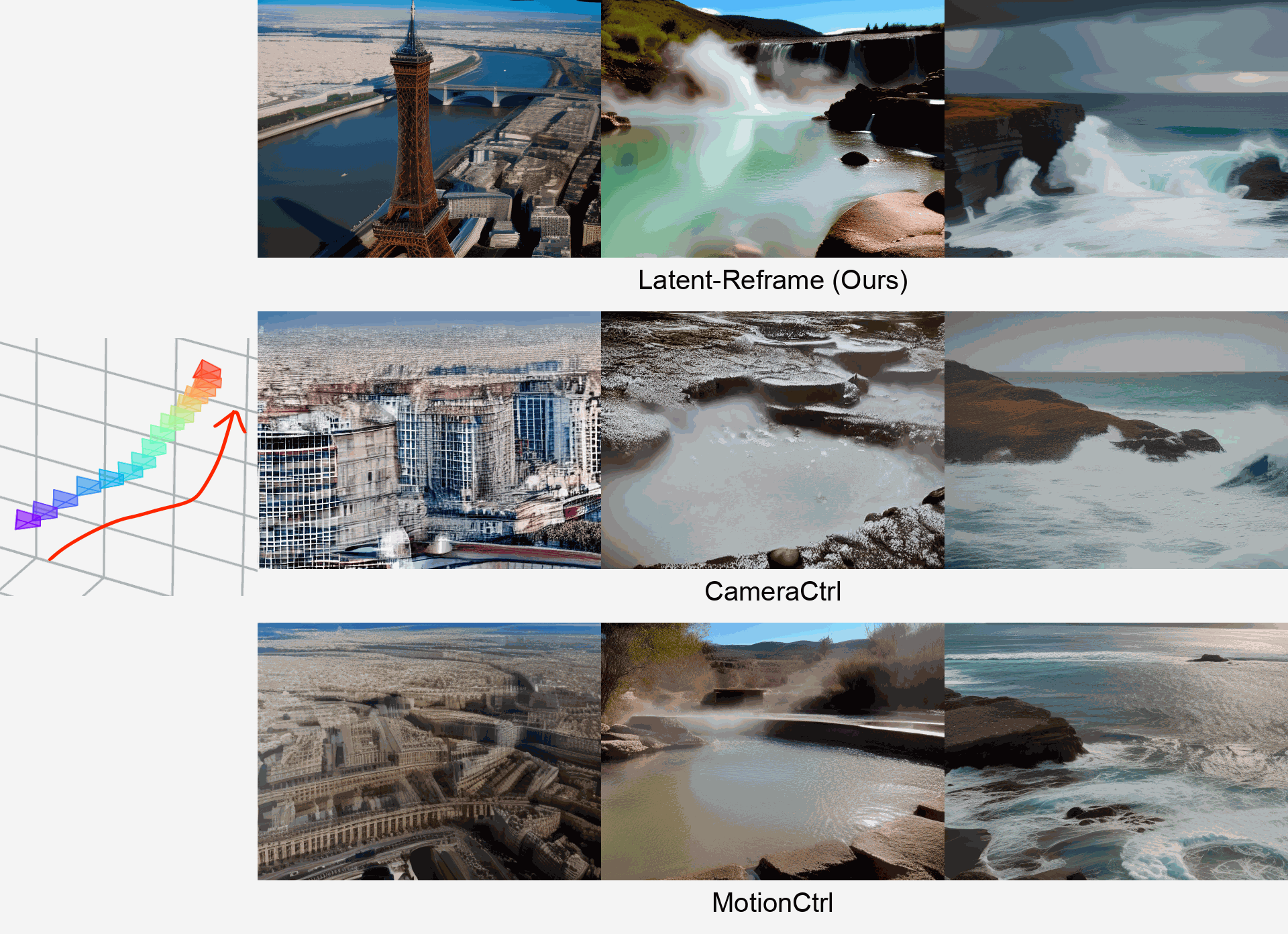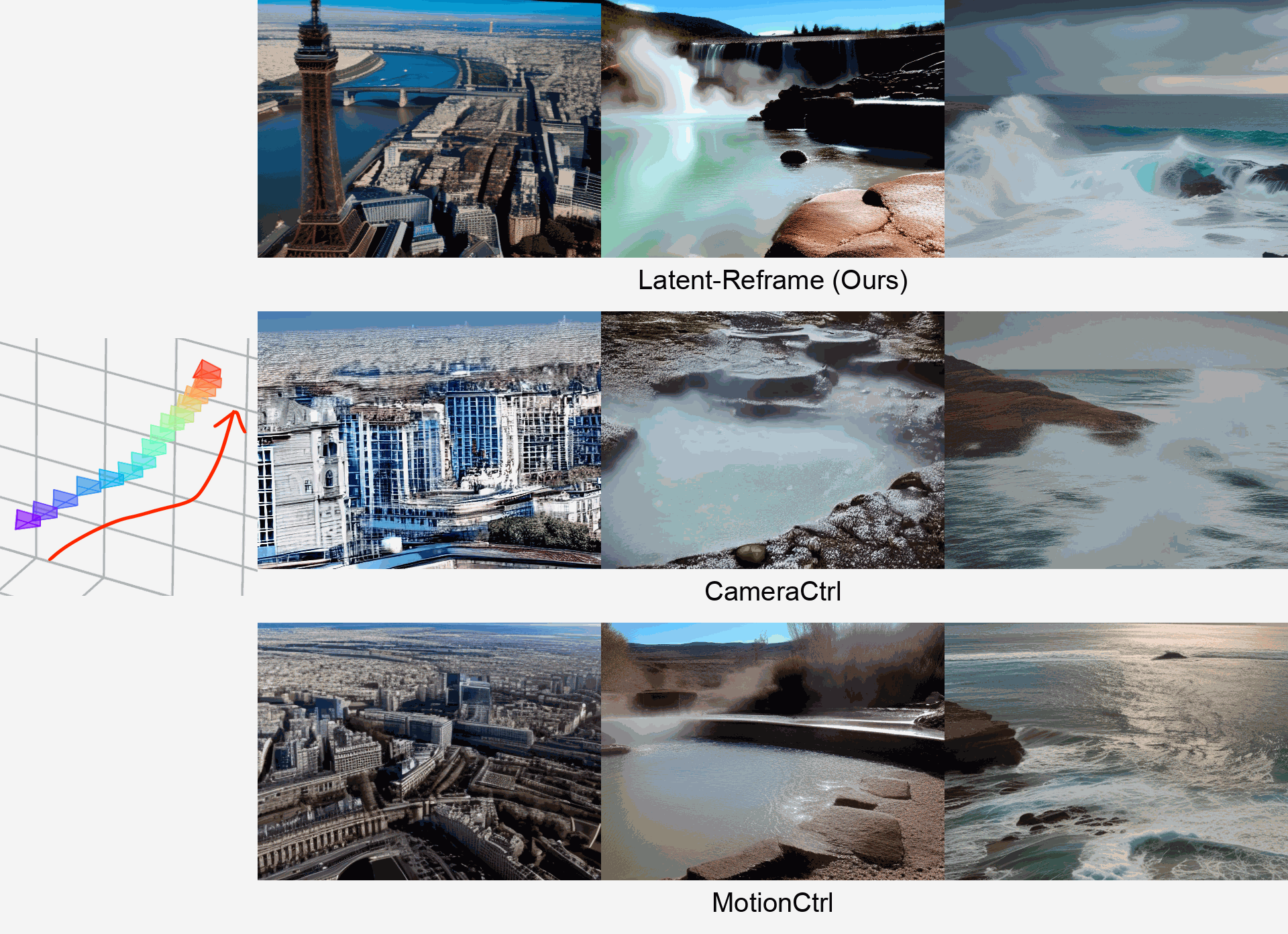
-
We propose Latent-Reframe, a method for enabling camera control
in video diffusion (such as T2V) models without requiring additional training.



Precise camera pose control is crucial for video generation with diffusion models. Existing methods require fine-tuning with additional datasets containing paired videos and camera pose annotations, which are both data-intensive and computationally costly, and can disrupt the pre-trained model’s distribution. We introduce Latent-Reframe, which enables camera control in a pre-trained video diffusion model without fine-tuning. Unlike existing methods, Latent-Reframe operates during the sampling stage, maintaining efficiency while preserving the original model distribution. Our approach reframes the latent code of video frames to align with the input camera trajectory through time-aware point clouds. Latent code inpainting and harmonization then refine the model's latent space, ensuring high-quality video generation. Experimental results demonstrate that Latent-Reframe achieves comparable or superior camera control precision and video quality to training-based methods, without the need for fine-tuning on additional datasets.